Bootstrapping Terraform GitHub Actions for AWS
Bootstrapping all Terraform required components to run and manage itself in GitHub Actions for AWS.


In a journey to eliminate all clickops, I want to automate the deployment of the core of my AWS infra with GitHub Actions. To do this, I need to create the IDP, IAM roles, the S3 bucket for the state, and the DynamoDB table for locking.
Terraform uses these, so it's a bit like the chicken and egg problem.
In this post, I will make Terraform manage its dependencies and connect GitHub Actions to AWS.
Bootstrapping the basics
Let's set up a skeleton for our Terraform configuration. The goal is to be able to:
- Create the requirements for a remote state from Terraform
- Authenticate to AWS using OIDC
- Run Terraform in GitHub Actions
Creating the S3 and DynamoDB Terraform
Terraform uses S3 for its state and a DynamoDB table to prevent simultaneous runs. These do not exist already, and we don't want to create them by hand. This is why the first module I created in my AWS Core Terraform config repository is remote-state. This module has to be bootstrapped, and the state must eventually be migrated to the created S3 bucket.
This module is responsible for creating the needed resources and generating the backend.tf file.
To set up the required components, I used the following Terraform code:
resource "random_id" "tfstate" {
byte_length = 8
}
resource "aws_s3_bucket" "terraform_state" {
bucket = "tfstate-${random_id.tfstate.hex}"
lifecycle {
prevent_destroy = true
}
}
resource "aws_s3_bucket_versioning" "terraform_state" {
bucket = aws_s3_bucket.terraform_state.id
versioning_configuration {
status = "Enabled"
}
}
resource "aws_dynamodb_table" "terraform_state_lock" {
name = "app-state-${random_id.tfstate.hex}"
hash_key = "LockID"
billing_mode = "PAY_PER_REQUEST"
attribute {
name = "LockID"
type = "S"
}
}remote-state module
To make the bucket name unique, I created a random ID, which is eventually saved in the Terraform state and will not change on subsequent runs.
For the DynamoDB table, I've set it up using PAY_PER_REQUEST because Terraform will not use even one query per second, and provisioning anything will likely result in more costs.
The attribute we're setting is the LockID which Terraform needs.
Next, we need Terraform to create the backend.tf file after it creates its required components.
I created this short template as state-backend.tftpl:
terraform {
backend "s3" {
bucket = "${bucket}"
key = "states/terraform.tfstate"
encrypt = true
dynamodb_table = "${dynamodb_table}"
region = "${region}"
}
}state-backend.tftpl
The templatefile function can template this template.
resource "local_sensitive_file" "foo" {
content = templatefile("${path.module}/state-backend.tftpl", {
bucket = aws_s3_bucket.terraform_state.id
dynamodb_table = aws_dynamodb_table.terraform_state_lock.name
region = var.aws_region
})
filename = "${path.module}/../../backend.tf"
}templatefile function
You can find the complete Terraform code here.
Bootstrapping the remote state
When we run the remote-state module, we see that Terraform is creating everything as we'd expect:
~$ terraform apply -target module.remote-state
Terraform used the selected providers to generate the following execution plan. Resource actions are indicated with the following symbols:
+ create
Terraform will perform the following actions:
# module.remote-state.aws_dynamodb_table.terraform_state_lock will be created
+ resource "aws_dynamodb_table" "terraform_state_lock" {
+ arn = (known after apply)
+ billing_mode = "PAY_PER_REQUEST"
+ hash_key = "LockID"
+ id = (known after apply)
+ name = (known after apply)
+ read_capacity = (known after apply)
+ stream_arn = (known after apply)
+ stream_label = (known after apply)
+ stream_view_type = (known after apply)
+ tags_all = (known after apply)
+ write_capacity = (known after apply)
+ attribute {
+ name = "LockID"
+ type = "S"
}
}
# module.remote-state.aws_s3_bucket.terraform_state will be created
+ resource "aws_s3_bucket" "terraform_state" {
+ acceleration_status = (known after apply)
+ acl = (known after apply)
+ arn = (known after apply)
+ bucket = (known after apply)
+ bucket_domain_name = (known after apply)
+ bucket_regional_domain_name = (known after apply)
+ force_destroy = true
+ hosted_zone_id = (known after apply)
+ id = (known after apply)
+ object_lock_enabled = (known after apply)
+ policy = (known after apply)
+ region = (known after apply)
+ request_payer = (known after apply)
+ tags_all = (known after apply)
+ website_domain = (known after apply)
+ website_endpoint = (known after apply)
}
# module.remote-state.aws_s3_bucket_versioning.terraform_state will be created
+ resource "aws_s3_bucket_versioning" "terraform_state" {
+ bucket = (known after apply)
+ id = (known after apply)
+ versioning_configuration {
+ mfa_delete = (known after apply)
+ status = "Enabled"
}
}
# module.remote-state.local_sensitive_file.foo will be created
+ resource "local_sensitive_file" "foo" {
+ content = (sensitive value)
+ directory_permission = "0700"
+ file_permission = "0700"
+ filename = "modules/remote-state/../../backend.tf"
+ id = (known after apply)
}
# module.remote-state.random_id.tfstate will be created
+ resource "random_id" "tfstate" {
+ b64_std = (known after apply)
+ b64_url = (known after apply)
+ byte_length = 8
+ dec = (known after apply)
+ hex = (known after apply)
+ id = (known after apply)
}
Plan: 5 to add, 0 to change, 0 to destroy.Terraform apply
However, because we generated and placed the backend.tf file, we see a warning when running it the second time:
│ Error: Backend initialization required, please run "terraform init"
│
│ Reason: Initial configuration of the requested backend "s3"To migrate the local state to the just created S3 bucket, we can use the following command:
~$ terraform init -migrate-state
Initializing the backend...
Do you want to copy existing state to the new backend?
Pre-existing state was found while migrating the previous "local" backend to the newly configured "s3" backend. No existing state was found in the newly configured "s3" backend. Do you want to copy this state to the new "s3" backend?
Enter "yes" to copy and "no" to start with an empty state.
Enter a value: yes
Successfully configured the backend "s3"! Terraform will automatically
use this backend unless the backend configuration changes.
Initializing modules...
Initializing provider plugins...
- Reusing previous version of hashicorp/random from the dependency lock file
- Reusing previous version of hashicorp/local from the dependency lock file
- Reusing previous version of hashicorp/aws from the dependency lock file
- Using previously-installed hashicorp/random v3.6.0
- Using previously-installed hashicorp/local v2.2.2
- Using previously-installed hashicorp/aws v4.37.0
Terraform has been successfully initialized!After the migration, you should be able to rerun it without any expected changes:
~$ terraform apply -target module.remote-state
module.remote-state.random_id.tfstate: Refreshing state... [id=_q9zfFjtnUQ]
module.remote-state.aws_dynamodb_table.terraform_state_lock: Refreshing state... [id=app-state-feaf737c58ed9d44]
module.remote-state.aws_s3_bucket.terraform_state: Refreshing state... [id=tfstate-feaf737c58ed9d44]
module.remote-state.aws_s3_bucket_versioning.terraform_state: Refreshing state... [id=tfstate-feaf737c58ed9d44]
module.remote-state.local_sensitive_file.foo: Refreshing state... [id=6a30000a63c0f6d2d5ef8be77cce05bdfc237df7]
No changes. Your infrastructure matches the configuration.
Terraform has compared your real infrastructure against your configuration and found no differences, so no changes are needed.We have a remote state which we can use in GitHub Actions now 🎉
Setting up a GitHub Actions Pipeline for Terraform
Although it might seem the wrong way around, I want to set up a Terraform pipeline before configuring the authentication from GitHub Actions to AWS. By having a broken pipeline, we can test the configuration we will build more easily.
To start using GitHub actions, we create a directory .github/workflows and place a yaml file there. You can find mine here.
The workflow consists of two jobs: the plan job and the apply job. The hard requirements I have for this workflow are:
- Run the
planjob on every commit - Merging is only available if the plan succeeds
- Run the
applyjob only on the main branch - Run the
applyjob only if there are changes - Require manual approval for the
applyjob to run - No use of access keys
- Account ID not visible
Most of these are straightforward, and the comments in GitHub should explain enough. Some were more interesting.
Merging is only available if the plan succeeds
It's good practice to prevent pushes to the main branch. You can block pushes by using branch protection rules. I chose to:
- Require a pull request before merging
- Require conversation resolution before merging
- Require linear history
- Require deployments to succeed before merging
- Do not allow bypassing the above settings
The most relevant options selected are options 1 and 4. These ensure everything will be funneled through a pull request only if the workflow succeeds.
Run the apply job only if there are changes
When you change things like placing comments, it will not change the outcome of the terraform plan. In that case, we can skip the apply step.
The Terraform setup wrapper sets a couple of outputs in GitHub Actions. The most interesting one for this requirement is the steps.plan.outputs.exitcode. This is set as an output in the plan job, and in the apply job, we can use it as a run condition.
apply:
runs-on: ubuntu-latest
environment: production
needs: plan
if: |
github.ref == 'refs/heads/main' &&
needs.plan.outputs.returncode == 2if using the main branch and changes are detected in the Terraform plan
Require manual approval for the apply job to run
A few GitHub bot scripts/actions allow you to open issues and place "LGTM!" comments to approve the next step: apply. I disliked how you use comments to approve steps, although it can be marked up nicely if you prefer this way.
GitHub allows you to review jobs that are in specific environments. To enable this, you open the settings tab in your repository and select Environments. You can add new environments if they are not already created automatically here. I created plan and apply.
Once they are created, you can enable the option Required reviewers and add yourself to the reviewers' list.
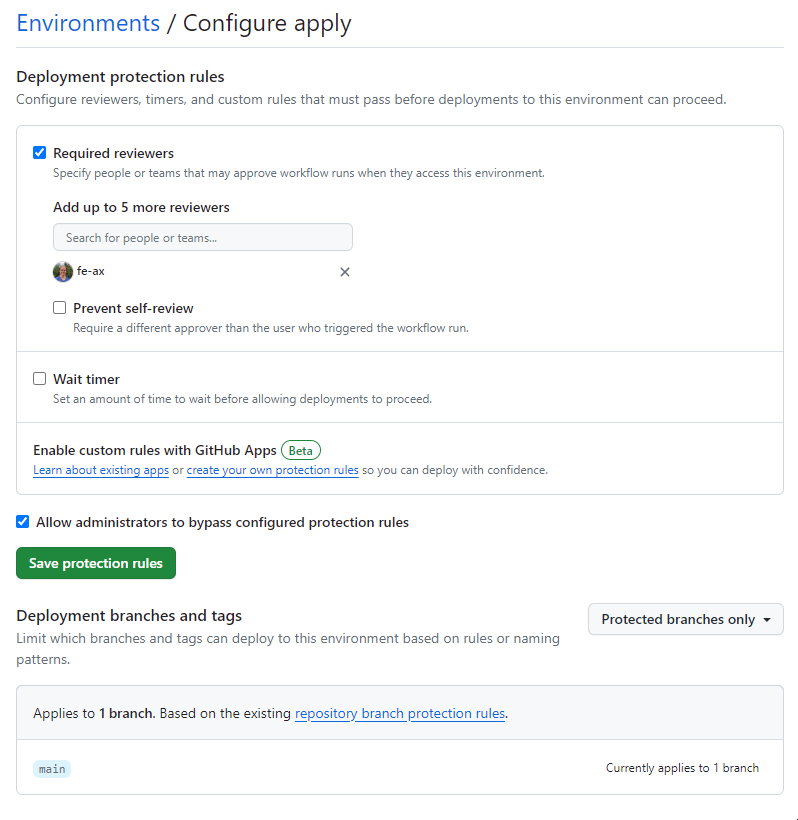
Concluding the GitHub Action pipeline
Now, we can run Terraform from GitHub actions and check the plan before we apply! 🎉
We're also probably very happy to see the following error in the pipeline:
Assuming role with OIDC
Error: Could not assume role with OIDC: No OpenIDConnect provider found in your account for https://token.actions.githubusercontent.comThis means that not everyone can access our AWS account. Let's dive into establishing a trust relationship between AWS and GitHub Actions.
Terraform warns you that running plan and apply separately without writing a plan to file may change the actual apply. This is because when you don't write your plan to a file, you cannot be certain that by the time you approve your rollout to production, your AWS state will still be the same.
When you run the plan command with -out, you can make sure that the apply step only applies what you had planned if the state didn't change.
Trusting the GitHub repository using OIDC
We must add an identity provider (IDP) to our AWS account to establish trust. This cannot be done from the GitHub actions we created because it has no access yet.
Adding the identity provider to AWS using Terraform
To create the IDP, we can always use the same Terraform code:
resource "aws_iam_openid_connect_provider" "default" {
url = "https://token.actions.githubusercontent.com"
client_id_list = [
"sts.amazonaws.com",
]
thumbprint_list = ["1b511abead59c6ce207077c0bf0e0043b1382612"]
}Identity provider in Terraform
I have followed this guide and placed the IDP here for this part. This allows GitHub to assume roles when the role trusts GitHub. The thumbprint_list contains GitHub's thumbprint and will always be the same.
Creating a role for Github to assume
Creating roles with Terraform consists of a lot of lines of code. You can read the whole config here. I will only discuss the trust policy here.
data "aws_iam_policy_document" "core_trusted_entities_policy_document" {
statement {
actions = ["sts:AssumeRoleWithWebIdentity"]
principals {
type = "Federated"
identifiers = [var.oidc_id_github]
}
condition {
test = "StringEquals"
variable = "token.actions.githubusercontent.com:aud"
values = ["sts.amazonaws.com"]
}
condition {
test = "StringEquals"
variable = "token.actions.githubusercontent.com:sub"
values = [
"repo:fe-ax/tf-aws:environment:plan",
"repo:fe-ax/tf-aws:environment:apply"
]
}
}
}Trust policy for GHA
A trust policy always needs to select a principal, which is a federated principal, since we're linking to GitHub.
Next, we must add a condition allowing GitHub to send requests for the AWS STS (Security Token Service) service.
Finally, we specify which environments can access this role. I chose not to split up the read/write roles of the plan/apply jobs, but it would be good practice to do this. Using the condition "StringEquals" will check against exact matches in one of the following values.
Applying the configuration
When everything is ready, we can locally run terraform apply to apply all the new additions and take the last step before running our GitHub Actions workflow successfully.
Testing the GitHub Actions workflow
The time has come to put everything to the test. First, push everything to a branch if you haven't already done so. Then, create a pull request from your branch to the main.
It should start running like this:
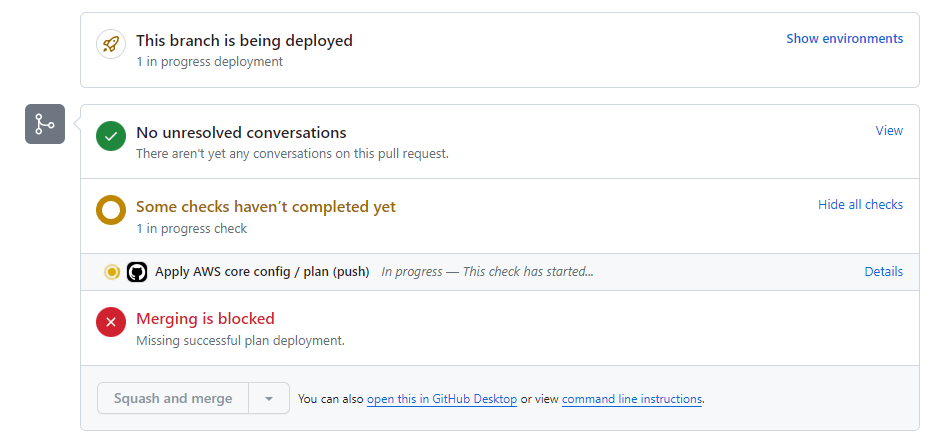
Showing the merge is blocked until the run is complete. After a couple of seconds, it should show:
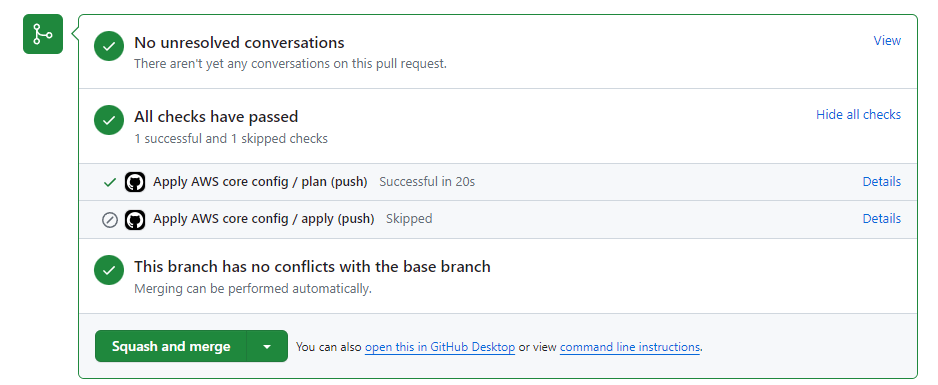
Check your plan, followed by a squash and merge. Don't forget to delete the branch. Immediately after merging, another plan should start running, detecting changes and triggering the apply job. It should look like:
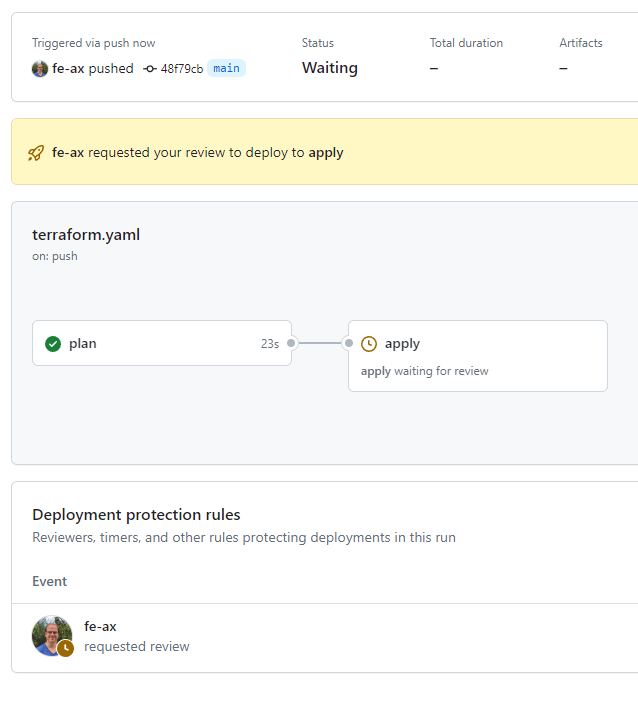
Check the plan again, approve the deployment, and 🎉GitHub Actions is managing its resources to be able to manage its resources!
Destroying everything
If you want to destroy everything again, you must remove the lifecycle_policy first, or Terraform will tell you you can't destroy anything.
The best route is to delete the backend.tf file and migrate the remote state to your local machine. This is needed because Terraform will be destroying its S3 state and DynamoDB lock table, losing your state in the middle of a run.
marco@DESKTOP-2RFLM66:~/tf-aws-iam/terraform$ rm backend.tf
marco@DESKTOP-2RFLM66:~/tf-aws-iam/terraform$ tf init -migrate-state
Initializing the backend...
Terraform has detected you're unconfiguring your previously set "s3" backend.
Do you want to copy existing state to the new backend?
Pre-existing state was found while migrating the previous "s3" backend to the
newly configured "local" backend. No existing state was found in the newly
configured "local" backend. Do you want to copy this state to the new "local"
backend? Enter "yes" to copy and "no" to start with an empty state.
Enter a value: yes
Successfully unset the backend "s3". Terraform will now operate locally.
Initializing modules...
Initializing provider plugins...
- Reusing previous version of hashicorp/random from the dependency lock file
- Reusing previous version of hashicorp/local from the dependency lock file
- Reusing previous version of hashicorp/aws from the dependency lock file
- Using previously-installed hashicorp/aws v4.37.0
- Using previously-installed hashicorp/random v3.6.0
- Using previously-installed hashicorp/local v2.2.2
Terraform has been successfully initialized!
You may now begin working with Terraform. Try running "terraform plan" to see
any changes that are required for your infrastructure. All Terraform commands
should now work.
If you ever set or change modules or backend configuration for Terraform,
rerun this command to reinitialize your working directory. If you forget, other
commands will detect it and remind you to do so if necessary.Terraform migrate
When the state is back to your local machine. Just destroy everything using terraform destroy and everything will be completely removed.
Conclusion
I think using GitHub as a place to manage anything and everything that's in your account is the only way to go. Clickopsing results in rogue resources that cannot be managed.
Whenever I have clickopsed things in a testing account, I use the aws-nuke script to find and remove all leftover AWS resources.
Further enhancements could be added to this setup, like making sure that the plan job only has read-only access, and the apply job with read-write access can only be run from the main branch.
Versions used
Terraform 1.7.0